
What is a dataset?
A dataset is a structured collection of data organised and stored together. Data within a dataset is typically related in some way. It can include different types or formats of data and may be comprised of one or many files.
To decide if you have one dataset or many, think about how you will describe the data and what the supporting documentation will consist of. If the metadata is similar or identical for each dataset, it indicates that you probably have one dataset. For example, if you have repeated the same experiment/monitoring event at several locations, this is likely to be be one dataset. Similarly, if you have carried out the same experiment/monitoring event over several years, this too could be one dataset, rather than several.
As part of the deposit process we will agree with you the format and structure of your data and a handover date. Ensuring that your data are correct and well-formatted will help to speed up the process.
Format
Data provided to the EIDC should normally be in a non-proprietary format (e.g. .csv(s) rather than an Excel workbook)
We maintain a list of acceptable formats, however the list is not exhaustive and we will consider other formats on a case-by-case basis.
Filenames
- Try to keep filenames short
- Do not use spaces. Replace them with underscores or hyphens (e.g. windermere_chemistry_data, windermere-chem-data) or use camel case (e.g. windermereChemistryData)
- Other than hyphens and underscores, avoid non-alphanumeric characters ($*@%”\/?*<>#^¾ etc.)
- If possible, filenames should be meaningful and reflect the content
- If you have multiple, related files be consistent and use a naming convention
Examples
1486Xiuytr.csv
This doesn't tell us anything about the data
Site location data from the UK Butterfly Monitoring Scheme collected during 2011.csv
This is very long and contains spaces
ukbmsLocationData2011.csv
This is descriptive, short and contains no spaces or special characters
Variables
- Variable names should be unique, short and (preferably) meaningful.
- Avoid spaces in variable names - consider using underscores in place. If you must use spaces, enclose the name in quotation marks ("")
- Avoid special characters (e.g. -$*@/, ) in variable names. Best practice is to use only alphanumeric characters and underscores (_).
- Remove any variables which are are not important for re-using the data (e.g. created for admin or internal purposes).
Examples
Sample ID
contains space
Sample_ID
Count of individual perch
contains spaces and is unnecessarily long
Perch_count
Binomial/Latin_name
contains non-standard character (/)
Binomial_name
Soil temperature ° C
contains spaces and non-standard character (°)
Soil_temp
Codelists and abbreviations
Using codes and abbreviations in the data is often very useful. However, if you do use them you must ensure:
- they are unique (within the dataset) and used consistently
- they are all described in the accompanying metadata
- Any explanations you provide in the metadata are applicable. For example, the metadata states "T = trace", but the code
Tdoesn't actually occur in the data.
Missing data/nulls
- It is preferable to identify nulls or missing data as blanks. However, depending on the format of the data this isn't always possible. Alternative ways of identifying nulls are to use codes such as NaN or N/A.
- Numerical values such as -999999 may also be acceptable but should be avoided if possible.
- Zeros (0) should NEVER be used to identify nulls as zero is a meaningful data value.
- Whatever method you use to identify nulls, it should be applied consistently throughout the dataset and must be documented in the accompanying metadata.
Tabular data
Structure
- We normally expect tabular data to be formatted with variables (mass, temperature, concentration etc) arranged in columns and observations in rows.
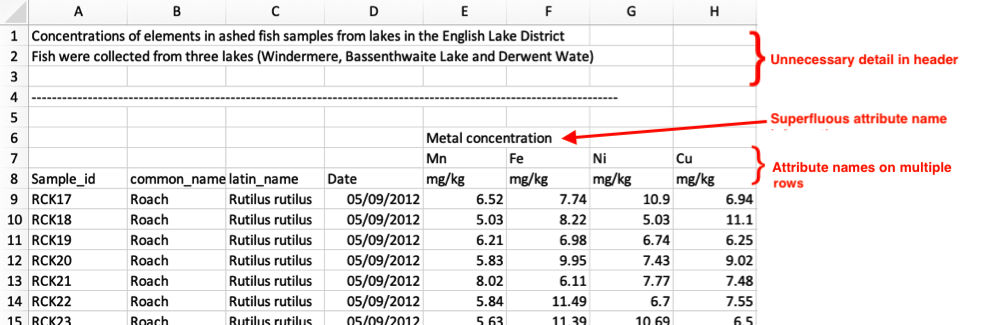
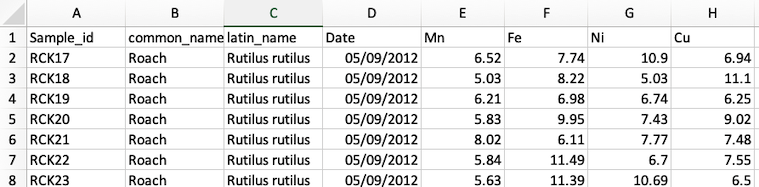
Headings
- Variable names should be in the first row (and only the first row). Data should follow in row 2.
- Remove superfluous information in heading rows.
|
|
 |
|
|
 |
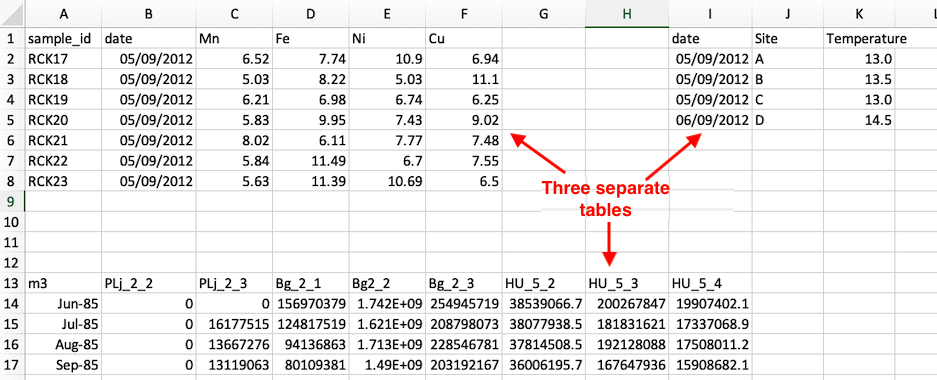
Multiple tables
- Never include more than one table within a single spreadsheet. This makes it far more difficult for a machine to read the data.
- Each table should be separated into its own file.
|
|
 |
Anonymity and data security
- Ensure that data are anonymised where needed and cannot be linked to any identifiable person
- Consider anonymising site location data where this is necessary for the safety of the site, equipment or future research
- Where data are derived from existing data, check if permission needs to be obtained from the data owner
Quality
- When converting data for deposit, ensure that all data and metadata are correct after conversion
- Confirm that data detail is consistent with the access and licensing agreements as stated
- Complete all internal consistency checks BEFORE offering your data for deposit
- Resolve any data issues and ensure data are complete BEFORE deposit, to minimise the risk of further deposit(s) being necessary
If you have any queries or are unsure about the suitability of your dataset(s) for deposit, we'll be happy to discuss it with you. Please contact us.