
Metadata provides essential information that enables a user to find out if a particular dataset exists, whether it meets their requirements and how to access it. Searches on data catalogues search engines can result in a large number of results. Metadata should therefore be sufficiently clear and comprehensible to differentiate your particular dataset, to enable the reader to understand its nature and to assess whether it is suitable for their use. Poor quality metadata can mean that a resource is effectively hidden from users and remains unused.
When writing good quality metadata, remember the ABCD. Metadata should be:
Accurate
It correctly and precisely describes the data
Beneficial
It contains information that is useful to the user and doesn’t have lots of extraneous, irrelevant information.
Clear
It is easily understandable and unambiguous. Write for readers not robots.
Distinctive
It allows the data to be distinguished from other, potentially similar, datasets.
Dataset titles
Provide a title that describes the data
The title should describe the dataset itself, it should not describe the project or activity from which the data were derived.
Drivers of metal accumulation in the Eurasian otter, a sentinel of freshwater ecosystems
This title describes what the data has been used for rather than describing the data itself. It sounds like a study or an article in a journal, rather than a dataset so it's not a good title. A better one might be:
Biological characteristics, liver metal concentrations, habitat biogeochemistry and habitat contamination sources of UK otters 2006-2017
This is much better. It describes exactly what was recorded, where and when.
Keep it brief
Only include information that is pertinent. Any additional information can be added to the dataset's description.
Ensure it is distinctive
It should contain enough information to distinguish it from other, possibly similar, titles.
Location, and date are important factors to consider
You might consider a title that answers the questions: "what, where, when".
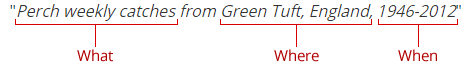
Avoid jargon
This is to provide clarity to the broadest possible audience.
Avoid using acronyms and abbreviations where possible…
If it is necessary to include acronyms, include both the acronym (in parentheses) and the phrase/word from which it was formed. For example: 'UK Environmental Change Network (ECN) soil solution chemistry data: 1992-2012'. Ask yourself - 'if the abbreviation were removed would it hinder understanding of the resource?'
…but common abbreviations may be acceptable
While acronyms or abbreviations should normally be explained, those that are in common usage need not always be spelled out.
Examples include (but are not limited to): UK EU UKCEH Defra NASA Laser Radar
Description
The description is an 'executive summary' that allows the reader to determine the relevance and usefulness of the resource. The text should be concise but should contain sufficient detail to allow the reader to easily determine the scope and limitations of the resource.
The description should describe the data resource in question… …NOT the project/activity which produced it.
Write for readers, not robots!
The description should be in plain English; in other words, write complete sentences rather than fragments. Keep sentences short - the average length of a sentence should be about 15-20 words
| Poor | Better |
|---|---|
| Moth abundance and pollen transport at sites lit by high-pressure sodium streetlights and unlit control sites sampled at 20 matched pairs of lit and unlit sites within 40 km of Wallingford, Oxfordshire, UK during 2014, as part of a study of the effects of street lighting on moths and nocturnal pollen transport. 3 sampling methods: night-time transects, light-traps and overhead flight activity surveys. Moths identified, counted, and sampled for pollen transported on the proboscis, which was in turn identified and counted. Supported by Natural Environment Research Council Grant NE/K007394/1 |
This dataset contains information about moth abundance and pollen transport at sites lit by high-pressure sodium streetlights and unlit control sites. Moths were sampled at 20 matched pairs of lit and unlit sites within 40 km of Wallingford, Oxfordshire, UK during 2014, as part of a study of the effects of street lighting on moths and nocturnal pollen transport. Three sampling methods were used: night-time transects, light-traps and overhead flight activity surveys. Moths captured were identified, counted, and sampled for pollen transported on the proboscis, which was in turn identified and counted. The work was supported by the Natural Environment Research Council (Grant NE/K007394/1). |
Who, what, when, where, how....
To help organise thinking, the author may like to use the following structure:
-
What
-
A description of what has been recorded and what form the data takes. This should immediately convey to the reader precisely what the resource is.
-
Where
-
A description of the spatial coverage. This should include, where relevant, whether the coverage is gridded or scattered data; whether the coverage is even or very variable.
-
When
-
A description of the temporal coverage (e.g. the period over which data were collected).
-
How
-
A brief description of methods and instrumentation used.
-
Why
-
For what purpose was the data collected?
-
Who
-
The party/parties responsible for the collection and interpretation of data. Individual names are not required, however, you may wish to add a project or programme name.
-
Completeness
-
Are any data absent from the dataset? Explain which data are included or excluded and why.
One or more of these elements may not always be applicable; if they are not applicable they can be omitted.
If you can't easily summarise or describe the resource it could be a sign that it isn’t fully understood.
Lineage
The lineage (or provenance) describes how the data came into existence and the stages it has passed through before being provided to the data centre. It should include information about the provenance, source(s), and/or the production processes applied to the resource. It may include brief details on any or all of the following:
- Fieldwork instrumentation used
- Methods of collection
- How values were arrived at (e.g. treatments etc.)
- Nature and units of recorded variables
- Processing steps performed on the data
- Quality control/assessment applied to the data
- Limitations on the data’s reliability
The purpose of the metadata record is for discovery and initial evaluation of the resource. Therefore chapter-and-verse is not required here. A maximum of 4000 characters is allowed but it's likely to be a lot shorter.
Detailed lineage and provenance information can be documented in supporting documentation.